確立了心法,也認識了江湖中的各路英雄,接下來我們要為寶貴的數據尋找一個安身之所。儲存數據的地方,我們統稱為「資料庫」,但隨著數據的種類和應用越來越多樣,光用「資料庫」一個詞已經不足以描述全貌。
今天,我們來拆解三個最關鍵的數據儲存架構:傳統資料庫 (Database)、資料倉儲 (Data Warehouse) 與資料湖 (Data Lake)。這三者不是互相取代,而是為了解決不同問題而生,尤其在 AI 時代,它們更是各司其職,共同支撐著複雜的 AI 應用。
| 特性 | 傳統資料庫 (Database) | 資料倉儲 (Data Warehouse) | 資料湖 (Data Lake) |
|---|---|---|---|
| 主要用途 | 線上交易處理 (OLTP) | 商業智慧分析 (BI) | AI 模型訓練、探索性分析 |
| 資料類型 | 結構化資料 | 結構化、已清理的資料 | 各種類型 (結構化、非結構化) |
| 資料結構 | Schema-on-Write (寫入前定義) | Schema-on-Write (寫入前定義) | Schema-on-Read (讀取時定義) |
| 使用者 | 應用程式、開發者 | 資料分析師、業務人員 | 資料科學家、資料工程師 |
| AI 應用情境 | 儲存電商訂單、會員資料 | 彙整銷售報表,分析顧客輪廓 | 儲存用戶評論(文字)、商品圖片 |
這是理解三者差異最核心的概念:
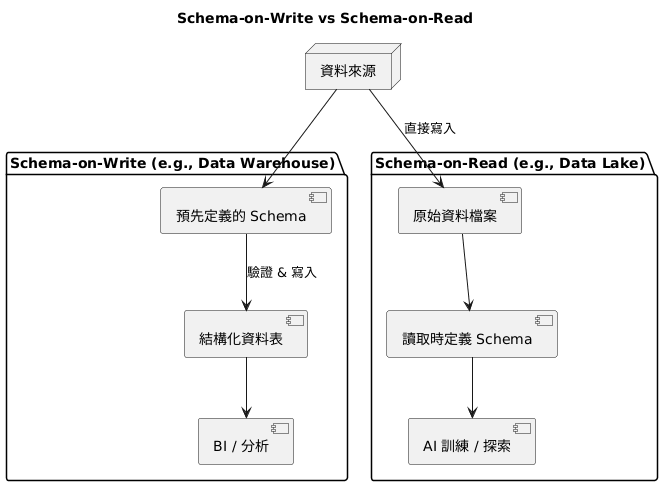
讓我們回到「智慧推薦系統」的例子:
如果沒有資料湖,AI 模型就失去了最豐富的養分。如果沒有資料倉儲,企業的日常營運分析將寸步難行。如果沒有傳統資料庫,整個交易系統都會崩潰。
選擇哪種儲存架構,取決於你的應用情境。萬丈高樓平地起,為你的數據選擇合適的家,是建構強大 AI 應用的第一步。下一階段我們會談到,如何融合兩者優點的現代架構 — Data Lakehouse。

